Map (ft. Hidden Class)
들어가며
자바스크립트를 활용해 개발 또는 알고리즘 문제를 풀다 보면 Map 객체를 사용해야 하는 경우가 많아요. 그런데, Map이 Object와 크게 다르지 않아 보이는데 독자 분들은 이 둘의 차이점에 대해 알고 계신가요? 이 글에서는 Map에 대해 알아보며, Object와의 차이점은 무엇이며 자바스크립트 엔진은 객체를 어떻게 최적화하는지 알아보려고 해요.
Map이란?
Map 객체는 키-값의 쌍을 저장하는 데이터 구조에요. new Map() 생성자를 통해 생성할 수 있으며, 여러 내장 기능을 제공해요.
const myMap = new Map();
Map 객체에 요소를 추가하고 싶다면 set() 메서드를 사용하면 돼요.
myMap.set('name', '일순신');
Map의 키는 유일해요. 따라서 같은 키로 여러 번 값을 설정하면 마지막 값으로 덮어 씌워져요.
myMap.set('name', '일순신');
myMap.set('name', '이순신'); // <<- 이 값으로 덮어씌워져요
Map 객체가 제공하는 주요 메서드는 아래와 같아요.
- map.set(key, value) : 값 저장
- map.get(key) : key에 해당하는 값 반환
- map.has(key) : key 존재 여부에 따라 true or false 반환
- map.delete(key) : key에 해당하는 값 삭제
- map.clear() : 객체 안의 모든 요소 삭제
- map.size : 요소의 개수 반환
더 궁금한 Map의 기능이 있다면, 아래 MDN 문서를 참고하는 것을 추천드려요.
https://developer.mozilla.org/ko/docs/Web/JavaScript/Reference/Global_Objects/Map
Object와 Map의 차이
자바스크립트이 Object와 Map은 비슷해 보이지만, 몇 가지 차이점이 존재해요. 둘이 어떻게 다른지 아래 내용을 통해 알아봐요. 편의를 위해 Object와 Map은 다음 코드와 같이 정의되어 있다고 가정할게요.
const myMap = new Map();
const myObj = {};
키 유형
Object의 키는 String 또는 Symbol 만 가능해요. 반면, Map은 어떤 값이든 키로 사용할 수 있어요.(객체, 함수, 원시값 등)
myMap.set({ name: '홍길동' }, { id: 0 }); // 가능
myObj[{ name: '홍길동' }] = { id: 0 }; // 불가능
키 순서
Object의 키는 순서가 보장되지 않아요. 하지만 Map은 삽입 순서대로 키를 유지하는 이터러블 객체에요.
이터러블(Iterable) 객체란? 데이터를 순차적으로 반복할 수 있는 객체를 의미해요.
순회
Map은 이터러블 객체이므로 for..of나 forEach같은 반복문을 사용할 수 있어요. 반면 Object는 Object.keys()나 Object.entries()같은 메서드를 통해 간접적으로 순회해야 하며, 키 순서가 보장되지 않는다는 특징을 가지고 있어요.
myMap.forEach((item) => {
console.log(item);
});
직렬화
Object는 JSON.stringify()와 JSON.parse()를 사용해 JSON으로 직렬화하거나 역직렬화할 수 있어요. 하지만 Map은 기본적으로 지원되는 메서드가 없어요.
만약 Map 객체를 직렬화 하고 싶다면 배열 또는 객체로 변환한 후에 직렬화를 해야해요.
const myMap = new Map([
['id', 1],
['name', 'Gemini'],
]);
// 1. 직렬화 (Array로 변환)
const json = JSON.stringify(Array.from(myMap.entries()));
console.log(json); // [["id",1],["name","Gemini"]]
// 2. 역직렬화 (다시 Map으로 복구)
const restoredMap = new Map(JSON.parse(json));
Object와 Map 성능 비교
Object와 Map은 요소 추가/삭제 성능에서 차이를 보여요. 특히, 객체 프로퍼티의 빈번한 추가/삭제가 필요한 경우 Map이 Object보다 더 효율적이에요. 이 이유는 아래 히든 클래스에서 다룰 예정이니 끝까지 읽어주세요!
먼저 아래 코드의 실행 결과를 확인해서 Object와 Map의 성능 차이를 확인할 수 있어요.
const iterations = 1000000;
// Object 테스트
console.time('Object 추가/삭제');
for (let i = 0; i < iterations; i++) {
myObj[`key${i}`] = i;
}
for (let i = 0; i < iterations; i++) {
delete myObj[`key${i}`];
}
console.timeEnd('Object 추가/삭제');
// Map 테스트
console.time('Map 추가/삭제');
for (let i = 0; i < iterations; i++) {
myMap.set(`key${i}`, i);
}
for (let i = 0; i < iterations; i++) {
myMap.delete(`key${i}`);
}
console.timeEnd('Map 추가/삭제');
위 코드를 실행하면 약 200ms 정도 차이가 나는 결과를 볼 수 있어요.
![]()
그렇다면 어떠한 이유로 성능 차이가 발생하는 걸까요? 이 질문에 대한 답을 알아보기 위해 다음 챕터로 넘어가보아요.
자바스크립트의 성능 최적화
자바스크립트는 동적 타이핑 언어로, 런타임에 객체의 프로퍼티를 자유롭게 추가하거나 수정할 수 있는 유연성을 제공해요. 이로 인해 자바스크립트는 속성 접근 시 동적으로 프로퍼티를 조회해야 하는 특성을 지니고 있어요. 초기 자바스크립트 엔진은 객체를 해시 테이블 구조로 관리했으나, 현대 엔진(v8, SpiderMonkey 등)은 히든 클래스와 인라인 캐싱 같은 기법을 적용해 최적화를 하고 있어요.
전통적인 해시 테이블 기반 객체 속성 접근 방식은 다음과 같아요. 객체에서 x 라는 문자열 키에 해당하는 값을 찾는 과정을 예시로 들게요.
- 'x' 문자열을 해시 함수로 해싱하여 해시값을 생성해요.
- 생성한 해시값을 사용해 해시 테이블의 버킷 인덱스를 계산해요.
- 해당 버킷에 접근하여, 충돌이 발생한 경우 버킷 내에서 선형 탐색 또는 충돌 해결 방식을 수행해요.
- 키 문자열을 비교하여 일치하는 항목을 찾아요.
- 연결된 값을 반환해요.
히든 클래스
현대 자바스크립트 엔진(V8 등)은 히든 클래스를 활용해 객체의 속성 접근 성능을 최적화해요. 히든 클래스는 객체의 프로퍼티 구조, 프로퍼티 오프셋(메모리 내 위치), 그리고 프로퍼티 추가/삭제에 따른 전환 정보를 저장하고 있는 내부 데이터 구조에요. 이를 통해 V8은 객체 구조 변경 시 히든 클래스를 생성하거나 재사용해 성능을 높이고 있어요.
코드와 함께 히든 클래스가 어떻게 생성되고 사용되는지 알아봐요. 편의상 현대 자바스크립트 엔진은 V8로 표기할게요.
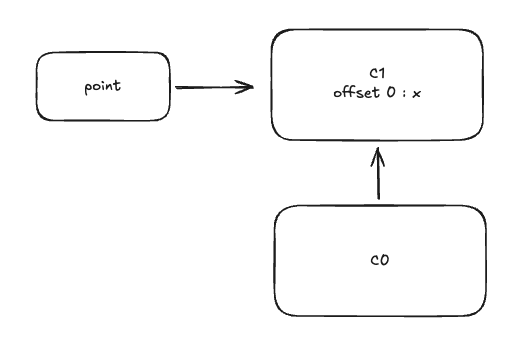
빈 객체를 생성하면 V8 엔진은 해당 객체에 대한 초기 히든 클래스(C0)를 생성해요. 이 시점의 히든 클래스는 아직 프로퍼티가 없어요.
const point = {};

객체에 x프로퍼티를 추가하면, V8 엔진은 기존 히든 클래스(C0)를 기반으로 새로운 히든 클래스(C1)를 생성해요. 히든 클래스(C1)은 프로퍼티 x와 메모리 오프셋 정보를 포함하며, C0 -> C1 전환 경로를 기록해요.
point.x = 10;
객체에 새로운 프로퍼티 y를 추가해요. V8은 기존 히든 클래스(C1)를 상속하여 또 다른 히든 클래스(C2)를 생성해요. 내부 구조는 히든 클래스(C1)과 동일해요.
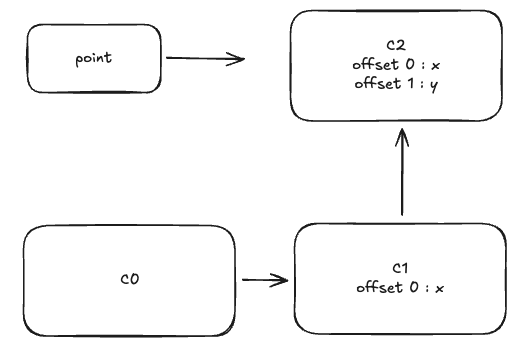
V8 엔진은 동일한 구조(같은 프로퍼티를 같은 순서로 추가한 객체)를 가진 객체들이 동일한 히든 클래스를 공유하도록 해요. 이를 통해 속성 접근 시 성능을 최적화하고 있어요.
주의할 점은 객체 프로퍼티티를 동일한 순서가 아닌 다른 순서로 추가하거나 삭제하면 히든 클래스를 재사용하지 못해요. 따라서 객체 구조를 일관되게 유지하는 것이 중요해요.
다만 객체의 프로퍼티가 빈번하게 추가/수정 될 경우 히든 클래스 생성 오버헤드를 유발해요. 따라서 객체의 프로퍼티가 빈번하게 변경되는 경우 Map이 더 유리하다.
인라인 캐싱
인라인 캐싱은 자주 사용되는 객체의 속성이나 메서드 접근 결과를 캐싱하여 동일한 접근이 발생했을 때 빠르게 결과를 제공해주는 최적화 기법이에요.
function getGeo(geo) {
const { x, y } = geo;
return [x, y];
}
const seoul = { x: 10, y: 10 };
const gyeonggido = { x: 5, y: 5 };
console.log(getGeo(seoul)); // 1번 호출
console.log(getGeo(gyeonggido)); // 2번 호출
1번 호출이 일어날 때 V8 엔진은 seoul 객체의 x, y 프로퍼티에 대한 접근을 캐싱해요. 그리고 2번 호출이 일어날 때 엔진은 gyeonggido 객체가 seoul 객체와 동일한 히든 클래스를 가진다는 것을 감지하고, 1번 호출에서 캐싱된 결과를 사용해 계산을 빠르게 수행해요.
마무리
객체 구조가 고정적이고 단순하며, JSON 직렬화가 필요하거나 프로토타입 상속을 활용해야 한다면 Object를 사용하는 것을 추천해요.
반면, 객체의 프로퍼티 추가/삭제가 빈번하게 발생하거나, 다양한 키 유형을 사용해야 하고, 이터러블한 특성이 필요하다면 Map이 유리해요.